一、什么是异常处理
二、为什么需要异常处理,以及异常处理的基本思想
C++之父Bjarne Stroustrup在《The C++ Programming Language》中讲到:一个库的作者可以检测出发生了运行时错误,但一般不知道怎样去处理它们(因为和用户具体的应用有关);另一方面,库的用户知道怎样处理这些错误,但却无法检查它们何时发生(如果能检测,就可以再用户的代码里处理了,不用留给库去发现)。
Bjarne Stroustrup说:提供异常的基本目的就是为了处理上面的问题。基本思想是:让一个函数在发现了自己无法处理的错误时抛出(throw)一个异常,然后它的(直接或者间接)调用者能够处理这个问题。
The fundamental idea is that a function that finds a problem it cannot cope with throws an exception, hoping that its (direct or indirect) caller can handle the problem.也就是《C++ primer》中说的:将问题检测和问题处理相分离。
Exceptions let us separate problem detection from problem resolution一种思想:在所有支持异常处理的编程语言中(例如java),要认识到的一个思想:在异常处理过程中,由问题检测代码可以抛出一个对象给问题处理代码,通过这个对象的类型和内容,实际上完成了两个部分的通信,通信的内容是“出现了什么错误”。当然,各种语言对异常的具体实现有着或多或少的区别,但是这个通信的思想是不变的。
三、异常出现之前处理错误的方式
在C语言的世界中,对错误的处理总是围绕着两种方法:一是使用整型的返回值标识错误;二是使用errno宏(可以简单的理解为一个全局整型变量)去记录错误。当然C++中仍然是可以用这两种方法的。
这两种方法最大的缺陷就是会出现不一致问题。例如有些函数返回1表示成功,返回0表示出错;而有些函数返回0表示成功,返回非0表示出错。
还有一个缺点就是函数的返回值只有一个,你通过函数的返回值表示错误代码,那么函数就不能返回其他的值。当然,你也可以通过指针或者C++的引用来返回另外的值,但是这样可能会令你的程序略微晦涩难懂。
四、异常为什么好
在如果使用异常处理的优点有以下几点:
1. 函数的返回值可以忽略,但异常不可忽略。如果程序出现异常,但是没有被捕获,程序就会终止,这多少会促使程序员开发出来的程序更健壮一点。而如果使用C语言的error宏或者函数返回值,调用者都有可能忘记检查,从而没有对错误进行处理,结果造成程序莫名其面的终止或出现错误的结果。
2. 整型返回值没有任何语义信息。而异常却包含语义信息,有时你从类名就能够体现出来。
3. 整型返回值缺乏相关的上下文信息。异常作为一个类,可以拥有自己的成员,这些成员就可以传递足够的信息。
4. 异常处理可以在调用跳级。这是一个代码编写时的问题:假设在有多个函数的调用栈中出现了某个错误,使用整型返回码要求你在每一级函数中都要进行处理。而使用异常处理的栈展开机制,只需要在一处进行处理就可以了,不需要每级函数都处理。
五、C++中使用异常时应注意的问题
任何事情都是两面性的,异常有好处就有坏处。如果你是C++程序员,并且希望在你的代码中使用异常,那么下面的问题是你要注意的。
1. 性能问题。这个一般不会成为瓶颈,但是如果你编写的是高性能或者实时性要求比较强的软件,就需要考虑了。
(如果你像我一样,曾经是java程序员,那么下面的事情可能会让你一时迷糊,但是没办法,谁叫你现在学的是C++呢。)
2. 指针和动态分配导致的内存回收问题:在C++中,不会自动回收动态分配的内存,如果遇到异常就需要考虑是否正确的回收了内存。在java中,就基本不需要考虑这个,有垃圾回收机制真好!
3. 函数的异常抛出列表:java中是如果一个函数没有在异常抛出列表中显式指定要抛出的异常,就不允许抛出;可是在C++中是如果你没有在函数的异常抛出列表指定要抛出的异常,意味着你可以抛出任何异常。
4. C++中编译时不会检查函数的异常抛出列表。这意味着你在编写C++程序时,如果在函数中抛出了没有在异常抛出列表中声明的异常,编译时是不会报错的。而在java中,eclipse的提示功能真的好强大啊!
5. 在java中,抛出的异常都要是一个异常类;但是在C++中,你可以抛出任何类型,你甚至可以抛出一个整型。(当然,在C++中如果你catch中接收时使用的是对象,而不是引用的话,那么你抛出的对象必须要是能够复制的。这是语言的要求,不是异常处理的要求)。
6. 在C++中是没有finally关键字的。而java和python中都是有finally关键字的。
六、异常的基本语法
1. 抛出和捕获异常
很简单,抛出异常用throw,捕获用try……catch。
捕获异常时的注意事项:
1. catch子句中的异常说明符必须是完全类型,不可以为前置声明,因为你的异常处理中常常要访问异常类的成员。例外:只有你的catch子句使用指针或者引用接收参数,并且在catch子句内你不访问异常类的成员,那么你的catch子句的异常说明符才可以是前置声明的类型。
2. catch的匹配过程是找最先匹配的,不是最佳匹配。
3. catch的匹配过程中,对类型的要求比较严格。不允许标准算术转换和类类型的转换。(类类型的转化包括两种:通过构造函数的隐式类型转化和通过转化操作符的类型转化)。
4. 和函数参数相同的地方有:
① 如果catch中使用基类对象接收子类对象,那么会造成子类对象分隔(slice)为父类子对象(通过调用父类的复制构造函数); ② 如果catch中使用基类对象的引用接受子类对象,那么对虚成员的访问时,会发生动态绑定,即会多态调用。 ③ 如果catch中使用基类对象的指针,那么一定要保证throw语句也要抛出指针类型,并且该指针所指向的对象,在catch语句执行是还存在(通常是动态分配的对象指针)。5. 和函数参数不同的地方有:
① 如果throw中抛出一个对象,那么无论是catch中使用什么接收(基类对象、引用、指针或者子类对象、引用、指针),在传递到catch之前,编译器都会另外构造一个对象的副本。也就是说,如果你以一个throw语句中抛出一个对象类型,在catch处通过也是通过一个对象接收,那么该对象经历了两次复制,即调用了两次复制构造函数。一次是在throw时,将“抛出到对象”复制到一个“临时对象”(这一步是必须的),然后是因为catch处使用对象接收,那么需要再从“临时对象”复制到“catch的形参变量”中; 如果你在catch中使用“引用”来接收参数,那么不需要第二次复制,即形参的引用指向临时变量。 ② 该对象的类型与throw语句中体现的静态类型相同。也就是说,如果你在throw语句中抛出一个指向子类对象的父类引用,那么会发生分割现象,即只有子类对象中的父类部分会被抛出,抛出对象的类型也是父类类型。(从实现上讲,是因为复制到“临时对象”的时候,使用的是throw语句中类型的(这里是父类的)复制构造函数)。 ③ 不可以进行标准算术转换和类的自定义转换:在函数参数匹配的过程中,可以进行很多的类型转换。但是在异常匹配的过程中,转换的规则要严厉。④ 异常处理机制的匹配过程是寻找最先匹配(first fit),函数调用的过程是寻找最佳匹配(best fit)。
2. 异常类型
上面已经提到过,在C++中,你可以抛出任何类型的异常。(哎,竟然可以抛出任何类型,刚看到到这个的时候,我半天没反应过来,因为java中这样是不行的啊)。
注意:也是上面提到过的,在C++中如果你throw语句中抛出一个对象,那么你抛出的对象必须要是能够复制的。因为要进行复制副本传递,这是语言的要求,不是异常处理的要求。(在上面“和函数参数不同的地方”中也讲到了,因为是要复制先到一个临时变量中)
3. 栈展开
栈展开指的是:当异常抛出后,匹配catch的过程。
抛出异常时,将暂停当前函数的执行,开始查找匹配的catch子句。沿着函数的嵌套调用链向上查找,直到找到一个匹配的catch子句,或者找不到匹配的catch子句。
注意事项:
1. 在栈展开期间,会销毁局部对象。
① 如果局部对象是类对象,那么通过调用它的析构函数销毁。
② 但是对于通过动态分配得到的对象,编译器不会自动删除,所以我们必须手动显式删除。(这个问题是如此的常见和重要,以至于会用到一种叫做RAII的方法,详情见下面讲述)
2. 析构函数应该从不抛出异常。如果析构函数中需要执行可能会抛出异常的代码,那么就应该在析构函数内部将这个异常进行处理,而不是将异常抛出去。
原因:在为某个异常进行栈展开时,析构函数如果又抛出自己的未经处理的另一个异常,将会导致调用标准库 terminate 函数。而默认的terminate 函数将调用 abort 函数,强制从整个程序非正常退出。
3. 构造函数中可以抛出异常。但是要注意到:如果构造函数因为异常而退出,那么该类的析构函数就得不到执行。所以要手动销毁在异常抛出前已经构造的部分。
4. 异常重新抛出
语法:使用一个空的throw语句。即写成: throw;
注意问题:
① throw; 语句出现的位置,只能是catch子句中或者是catch子句调用的函数中。
② 重新抛出的是原来的异常对象,即上面提到的“临时变量”,不是catch形参。 ③ 如果希望在重新抛出之前修改异常对象,那么应该在catch中使用引用参数。如果使用对象接收的话,那么修改异常对象以后,不能通过“重新抛出”来传播修改的异常对象,因为重新抛出不是catch形参,应该使用的是 throw e; 这里“e”为catch语句中接收的对象参数。5. 捕获所有异常(匹配任何异常)
语法:在catch语句中,使用三个点(…)。即写成:catch (…) 这里三个点是“通配符”,类似 可变长形式参数。
常见用法:与“重新抛出”表达式一起使用,在catch中完成部分工作,然后重新抛出异常。
6. 未捕获的异常
意思是说,如果程序中有抛出异常的地方,那么就一定要对其进行捕获处理。否则,如果程序执行过程中抛出了一个异常,而又没有找到相应的catch语句,那么会和“栈展开过程中析构函数抛出异常”一样,会 调用terminate 函数,而默认的terminate 函数将调用 abort 函数,强制从整个程序非正常退出。
7. 构造函数的函数测试块
对于在构造函数的初始化列表中抛出的异常,必须使用函数测试块(function try block)来进行捕捉。语法类型下面的形式:
MyClass::MyClass(int i)try :member(i) { //函数体} catch(异常参数) { //异常处理代码} 注意事项:在函数测试块中捕获的异常,在catch语句中可以执行一个内存释放操作,然后异常仍然会再次抛出到用户代码中。
8. 异常抛出列表(异常说明 exception specification)
就是在函数的形参表之后(如果是const成员函数,那么在const之后),使用关键字throw声明一个带着括号的、可能为空的 异常类型列表。形如:throw () 或者 throw (runtime_error, bad_alloc) 。
含义:表示该函数只能抛出 在列表中的异常类型。例如:throw() 表示不抛出任何异常。而throw (runtime_error, bad_alloc)表示只能抛出runtime_error 或bad_alloc两种异常。
注意事项:(以前学java的尤其要注意,和java中不太一样)
① 如果函数没有显式的声明 抛出列表,表示异常可以抛出任意列表。(在java中,如果没有异常抛出列表,那么是不能抛出任何异常的)。
② C++的 “throw()”相当于java的不声明抛出列表。都表示不抛出任何异常。
③ 在C++中,编译的时候,编译器不会对异常抛出列表进行检查。也就是说,如果你声明了抛出列表,即使你的函数代码中抛出了没有在抛出列表中指定的异常,你的程序依然可以通过编译,到运行时才会出错,对于这样的异常,在C++中称为“意外异常”(unexpeced exception)。(这点和java又不相同,在java中,是要进行严格的检查的)。
意外异常的处理:
如果程序中出现了意外异常,那么程序就会调用函数unexpected()。这个函数的默认实现是调用terminate函数,即默认最终会终止程序。虚函数重载方法时异常抛出列表的限制:
在子类中重载时,函数的异常说明 必须要比父类中要同样严格,或者更严格。换句话说,在子类中相应函数的异常说明不能增加新的异常。或者再换句话说:父类中异常抛出列表是该虚函数的子类重载版本可以抛出异常列表的 超集。函数指针中异常抛出列表的限制:
异常抛出列表是函数类型的一部分,在函数指针中也可以指定异常抛出列表。但是在函数指针初始化或者赋值时,除了要检查返回值和形式参数外,还要注意异常抛出列表的限制:源指针的异常说明必须至少和目标指针的一样严格。比较拗口,换句话说,就是声明函数指针时指定的异常抛出列表,一定要实际函数的异常抛出列表的超集。 如果定义函数指针时不提供异常抛出列表,那么可以指向能够抛出任意类型异常的函数。抛出列表是否有用:
在《More effective C++》第14条,Scott Meyers指出“要谨慎的使用异常说明”(Use exception specifications judiciously)。“异常说明”,就是我们所有的“异常抛出列表”。之所以要谨慎,根本原因是因为C++编译器不会检查异常抛出列表,这样就可能在函数代码中、或者调用的函数中抛出了没有在抛出列表中指定的异常,从而导致程序调用unexpected函数,造成程序提前终止。同时他给出了三条要考虑的事情: ① 在模板中不要使用异常抛出列表。(原因很简单,连用来实例模板的类型都不知道,也就无法确定该函数是否应该抛出异常,抛出什么异常)。 ② 如果A函数内调用了B函数,而B函数没有声明异常抛出列表,那么A函数本身也不应该设定异常抛出列表。(原因是,B函数可能抛出没有在A函数的异常抛出列表中声明的异常,会导致调用unex函数); ③ 通过set_unexpected函数指定一个新的unexpected函数,在该函数中捕获异常,并抛出一个统一类型的异常。另外,在《C++ Primer》4th 中指出,虽然异常说明应用有限,但是如果能够确定该函数不会抛出异常,那么显式声明其不抛出任何异常 有好处。通过语句:"throw ()"。这样的好处是:对于程序员,当调用这样的函数时,不需要担心异常。对于编译器,可以执行被可能抛出异常所抑制的优化。
七、标准库中的异常类
All exceptions thrown from the language or the library are derived from the base class exception. This class is the root of several standard exception classes that form a hierarchy, as shown in Figure 3.1. These standard exception classes can be divided into three groups:(引自《C++ Standard Library》)
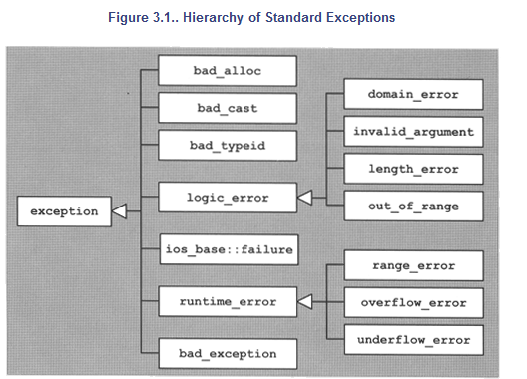
每个类所在的头文件在图下方标识出来.
标准异常类的成员:
① 在上述继承体系中,每个类都有提供了构造函数、复制构造函数、和赋值操作符重载。
② logic_error类及其子类、runtime_error类及其子类,它们的构造函数是接受一个string类型的形式参数,用于异常信息的描述; ③ 所有的异常类都有一个what()方法,返回const char* 类型(C风格字符串)的值,描述异常信息。| 异常名称 | 描述 |
| exception | 所有标准异常类的父类 |
| bad_alloc | 当operator new and operator new[],请求分配内存失败时 |
| bad_exception | 这是个特殊的异常,如果函数的异常抛出列表里声明了bad_exception异常,当函数内部抛出了异常抛出列表中没有的异常,这是调用的unexpected函数中若抛出异常,不论什么类型,都会被替换为bad_exception类型 |
| bad_typeid | 使用typeid操作符,操作一个NULL指针,而该指针是带有虚函数的类,这时抛出bad_typeid异常 |
| bad_cast | 使用dynamic_cast转换引用失败的时候 |
| ios_base::failure | io操作过程出现错误 |
| logic_error | 逻辑错误,可以在运行前检测的错误 |
| runtime_error | 运行时错误,仅在运行时才可以检测的错误 |
logic_error的子类:
| 异常名称 | 描述 |
| length_error | 试图生成一个超出该类型最大长度的对象时,例如vector的resize操作 |
| domain_error | 参数的值域错误,主要用在数学函数中。例如使用一个负值调用只能操作非负数的函数 |
| out_of_range | 超出有效范围 |
| invalid_argument | 参数不合适。在标准库中,当利用string对象构造bitset时,而string中的字符不是’0’或’1’的时候,抛出该异常 |
runtime_error的子类:
| 异常名称 | 描述 |
| range_error | 计算结果超出了有意义的值域范围 |
| overflow_error | 算术计算上溢 |
| underflow_error | 算术计算下溢 |
八、编写自己的异常类
1. 为什么要编写自己的异常类?
① 标准库中的异常是有限的; ② 在自己的异常类中,可以添加自己的信息。(标准库中的异常类值允许设置一个用来描述异常的字符串)。2. 如何编写自己的异常类?
① 建议自己的异常类要继承标准异常类。因为C++中可以抛出任何类型的异常,所以我们的异常类可以不继承自标准异常,但是这样可能会导致程序混乱,尤其是当我们多人协同开发时。 ② 当继承标准异常类时,应该重载父类的what函数和虚析构函数。 ③ 因为栈展开的过程中,要复制异常类型,那么要根据你在类中添加的成员考虑是否提供自己的复制构造函数。九、用类来封装资源分配和释放
为什么要使用类来封装资源分配和释放?
为了防止内存泄露。因为在函数中发生异常,那么对于动态分配的资源,就不会自动释放,必须要手动显式释放,否则就会内存泄露。而对于类对象,会自动调用其析构函数。如果我们在析构函数中显式delete这些资源,就能保证这些动态分配的资源会被释放。如何编写这样的类?
将资源的分配和销毁用类封转起来。在析构函数中要显式的释放(delete或delete[])这些资源。这样,若用户代码中发生异常,当作用域结束时,会调用给该类的析构函数释放资源。这种技术被称为:资源分配即初始化。(resource allocation is initialization,缩写为"RAII")。十、auto_ptr的使用(非常重要)
“用类封装资源的分配和释放”是如此的重要,C++标准库为我们提供了一个模板类来实现这个功能。名称为auto_ptr,在memory头文件中。
| 函数 | 功能 |
| auto_ptr <T> ap() | 默认构造函数,创建名为ap的未绑定的auto_ptr对象 |
| auto_ptr<T> ap(p); | 创建名为 ap 的 auto_ptr 对象,ap 拥有指针 p 指向的对象。该构造函数为 explicit |
| auto_ptr<T> ap1(ap2); | 创建名为 ap1 的 auto_ptr 对象,ap1 保存原来存储在 ap2 中的指针。将所有权转给 ap1,ap2 成为未绑定的 auto_ptr 对象 |
| ap1 = ap2 | 将所有权 ap2 转给 ap1。删除 ap1 指向的对象并且使 ap1 指向 ap2 指向的对象,使 ap2 成为未绑定的 |
| ~ap | 析构函数。删除 ap 指向的对象 |
| *ap | 返回对 ap 所绑定的对象的引用 |
| ap-> | 返回 ap 保存的指针 |
| ap.reset(p) | 如果 p 与 ap 的值不同,则删除 ap 指向的对象并且将 ap 绑定到 p |
| ap.release() | 返回 ap 所保存的指针并且使 ap 成为未绑定的 |
| ap.get() | 返回 ap 保存的指针 |
auto_ptr类的使用:
1. 用来保存一个指向对象类型的指针。注意必须是动态分配的对象(即使用new非配的)的指针。既不能是动态分配的数组(使用new [])指针,也不能是非动态分配的对象指针。 2. 惯用的初始化方法:在用户代码中,使用new表达式作为auto_ptr构造函数的参数。(注意:auto_ptr类接受指针参数的构造函数为explicit,所以必须显式的进行初始化)。 3. auto_ptr的行为特征:类似普通指针行为。auto_ptr存在的主要原因就是,为了防止动态分配的对象指针造成的内存泄露,既然是指针,其具有"*"操作符和"->"操作符。所以auto_ptr的主要目的就是:首先保证自动删除auto_ptr所引用的对象,并且要支持普通指针行为。 4. auto_ptr对象的复制和赋值是有破坏性的。① 会导致右操作数成为未绑定的,导致auto_ptr对象不能放到容器中;② 在赋值的时候,将有操作符修改为未绑定,即修改了右操作数,所以要保证这里的赋值操作符右操作数是可以修改的左值(然而普通的赋值操作符中,右操作数可以不是左值);③和普通的赋值操作符一样,如果是自我赋值,那么没有效果;④ 导致auto_ptr对象不能放到容器中。 5. 如果auto_ptr初始化的时候,使用默认构造函数,成为未绑定的auto_ptr对象,那么可以通过reset操作将其绑定到一个对象。 6. 如果希望测试auto_ptr是否已经绑定到了一个对象,那么使用get()函数的返回值与NULL进行比较。auto_ptr的缺陷:
1. 不能使用auto_ptr对象保存指向静态分配的对象的指针,也不能保存指向动态分配的数组的指针。 2. 不能讲两个auto_ptr对象指向同一个对象。因为在一个auto_ptr对象析构以后,造成另一个auto_ptr对象指向了已经释放的内存。造成这种情况的两种主要常见原因是:① 用同一个指针来初始化或者reset两个不同的auto_ptr对象;② 使用一个auto_ptr对象的get函数返回值去初始化或者reset另一个auto_ptr对象。 3. 不能将auto_ptr对象放到容器中。因为其复制和赋值操作具有破坏性。十一、常见的异常处理问题
动态内存分配错误
① 分配动态内存使用的是new和new[]操作符,如果他们分配内存失败,就会抛出bad_alloc异常,在new头文件中,所以我们的代码中应该捕捉这些异常。常见的代码形式如下:
- try {
- //其他代码
- ptr = new int[num_max];
- //其他代码
- } catch(bad_alloc &e) {
- //这里常见的处理方式为:先释放已经分配的内存,然后结束程序,或者打印一条错误信息并继续执行
- }
② 可以使用类似C语言的方式处理,但这时要使用的nothrow版本,使用"new (nothrow)"的形式分配内存。这时,如果分配不成功,返回的是NULL指针,而不再是抛出bad_alloc异常。
③ 可以定制内存分配失败行为。C++允许指定一个new 处理程序(newhandler)回调函数。默认的并没有new 处理程序,如果我们设置了new 处理程序,那么当new和new[] 分配内存失败时,会调用我们设定的new 处理程序,而不是直接抛出异常。通过set_new_handler函数来设置该回调函数。要求被回调的函数没有返回值,也没有形式参数。十二、来自C++之父Bjarne Stroustrup的建议
节选自《The C++ Programming Language》 ——C++之父Bjarne Stroustrup
1. Don’t use exceptions where more local control structures will suffice; 当局部的控制能够处理时,不要使用异常; 2. Use the "resource allocation is initialization" technique to manage resources; 使用“资源分配即初始化”技术去管理资源; 3. Minimize the use of try-blocks. Use "resource acquisition is initialization" instead of explicit handler code; 尽量少用try-catch语句块,而是使用“资源分配即初始化”技术。 4. Throw an exception to indicate failure in a constructor; 如果构造函数内发生错误,通过抛出异常来指明。 5. Avoid throwing exceptions from destructors; 避免在析构函数中抛出异常。 6. Keep ordinary code and error-handling code separate; 保持普通程序代码和异常处理代码分开。 7. Beware of memory leaks caused by memory allocated by new not being released in case of an exception; 小心通过new分配的内存在发生异常时,可能造成内存泄露。 8. Assume that every exception that can be thrown by a function will be thrown; 如果一个函数可能抛出某种异常,那么我们调用它时,就要假定它一定会抛出该异常,即要进行处理。 9. Don't assume that every exception is derived from class exception; 要记住,不是所有的异常都继承自exception类。 10. A library shouldn't unilaterally terminate a program. Instead, throw an exception and let a caller decide; 编写的供别人调用的程序库,不应该结束程序,而应该通过抛出异常,让调用者决定如何处理(因为调用者必须要处理抛出的异常)。 11. Develop an error-handling strategy early in a design; 若开发一个项目,那么在设计阶段就要确定“错误处理的策略”。